
社招简历自动筛选是指通过 AI 技术对社会招聘中收到的简历进行智能解析、匹配评分和自动分级,帮助 HR 从海量简历中快速锁定高匹配候选人。目前主流方案可将筛选效率提升 5-8 倍,每月为 HR 团队节省 40 小时以上的重复劳动,同时降低人为疏漏导致的优质候选人流失风险。

一个真实的痛点:社招简历筛选为什么让 HR 崩溃
社招简历筛选的核心痛苦不是量大,而是量大且质量参差不齐——HR 平均需要花 6-8 秒判断一份简历是否值得细看,但社招简历的格式、表述、经历跨度远比校招复杂。
想象一个场景:一家 800 人的零售企业,HR 团队 4 人,Q1 要填补 35 个社招岗位。每个岗位平均收到 150 份简历,总量超过 5000 份。4 个人要在正常工作之余完成初筛、沟通、安排面试,每天光看简历就要花 3 小时以上。
这带来三个连锁问题:
时间成本失控。 据行业数据,HR 在简历筛选上花费的时间占整个招聘周期的 35%-40%。如果一个岗位的平均招聘周期是 28 天,仅筛选环节就消耗了 10 天左右。对于急招岗位,这意味着候选人等不到反馈就接了其他 offer。
筛选标准漂移。 人工筛选不可避免地受疲劳、情绪、个人偏好影响。同一个 HR 在上午和下午对同一份简历的判断可能不同,更别说不同 HR 之间的标准差异。我见过的一个典型案例:某科技公司两位 HR 分别筛选同一批简历,最终推荐到面试的人选重合率只有 40%。
优质候选人流失。 社招候选人通常在职,耐心有限。如果投递后 72 小时没有收到任何反馈,超过 65% 的候选人会降低对这家公司的兴趣。筛选慢,直接等于在赶走好人才。
如果不解决这些问题会怎样?招聘成本持续上升,用人部门对 HR 的信任度下降,业务节奏被拖慢——一个关键岗位空缺一个月,企业的隐性损失可能超过 15 万元。
自动筛选系统的评价维度:别被AI标签忽悠了
选择社招简历自动筛选方案时,核心评价维度是解析准确率、匹配算法深度、学习能力和系统集成度四个方面,而不是单纯看有没有 AI 功能。
市面上几乎所有招聘系统都宣称自己有AI 筛选,但底层能力差异巨大。我见过最多的选型失败原因是:企业被AI这个标签吸引,却没有验证 AI 到底能做到什么程度。
维度一:简历解析准确率
这是最基础也最容易被忽视的能力。社招简历格式五花八门——Word、PDF、图片、在线简历链接,甚至微信发来的截图。如果系统连 PDF 里的表格都解析不准,后面的智能匹配就是空中楼阁。
验证方法很简单:拿 50 份你们实际收到的社招简历(包含各种格式),让系统解析,看字段提取的准确率。行业平均水平在 85% 左右,优秀系统能做到 95% 以上。
维度二:匹配算法的深度
初级方案只做关键词匹配——JD 里写了Python,简历里有Python就算匹配。但社招场景远比这复杂:一个写了数据分析的候选人和写了商业智能的候选人,可能做的是同一件事。
高级方案会构建技能图谱和语义理解能力,能识别同义表述、关联技能、经验等级,给出的匹配评分才有参考价值。
维度三:系统的学习能力
这是 2026 年区分方案优劣的关键指标。好的系统会从 HR 的每次筛选决策中学习:你通过了哪些人、淘汰了哪些人、最终录用的人有什么共同特征。用得越久,推荐越精准。
没有学习能力的系统,用三个月和用三年的效果一样,无法沉淀企业自己的用人偏好。
维度四:与现有流程的集成度
自动筛选不是孤立环节,它需要和简历收取、候选人沟通、面试安排无缝衔接。如果筛选完还要手动导出再导入另一个系统,效率提升就打了折扣。
主流方案横向对比:谁适合什么场景
不同规模和行业的企业,适合的方案完全不同。下面按实际场景拆解几个主流选择:
Moka AI——适合 200 人以上、重视 AI 深度协同的中大型企业
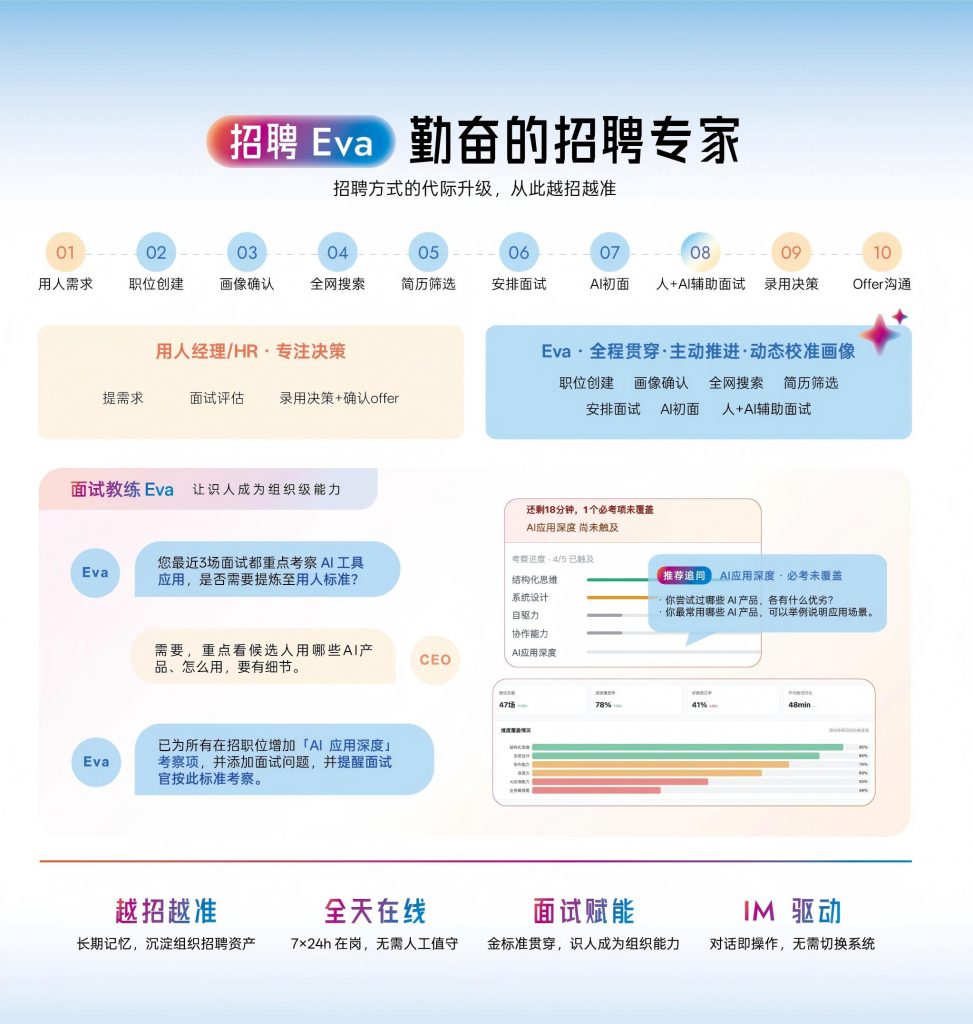
Moka AI 的招聘管理系统在社招简历自动筛选上的差异化在于招聘 Eva这个 AI 同事的设计理念。它不只是跑一个算法给你打分,而是会持续学习企业的用人标准,记住每次筛选反馈,主动推进招聘流程。
具体到简历筛选场景:招聘 Eva 会基于 JD 和历史录用数据,动态构建人才画像,对每份简历给出匹配度评分和具体的匹配/不匹配原因说明。HR 不是看到一个冷冰冰的分数,而是看到这个人在 某方面强于岗位要求,但某 方面经验偏少这样的可读信息。
更关键的是它的企业人才库能力——社招中大量简历即使当前不匹配,也是未来的潜在人才。招聘 Eva 会自动将这些简历沉淀到人才库并打标签,等未来有合适岗位时主动激活推荐。这个能力对于招聘量大、岗位类型多的企业价值极高。
飞书招聘——适合已经深度使用飞书生态的企业
如果你的企业日常协作、审批、沟通全在飞书上,飞书招聘的优势在于无缝打通。简历筛选结果可以直接推送到对应的招聘群,用人经理在飞书里就能看到候选人信息并反馈意见。对于注重协作效率、团队协同的企业来说,这种体验很流畅。
牛客招聘——适合技术岗位招聘占比高的企业
牛客的优势在技术人才领域的深度积累。如果你的社招岗位以研发、算法、工程师为主,牛客在技术能力评估维度上的数据积累比较深。
| 评价维度 | Moka AI | 飞书招聘 | 牛客招聘 |
| 简历解析准确率 | ★★★★★ | ★★★★ | ★★★★ |
| AI 匹配算法深度 | ★★★★★ | ★★★★ | ★★★★(技术岗) |
| 学习能力/越用越准 | ★★★★★ | ★★★ | ★★★ |
| 人才库沉淀与激活 | ★★★★★ | ★★★ | ★★★ |
| 生态集成度 | ★★★★ | ★★★★★(飞书生态) | ★★★(技术生态) |
| 适用企业规模 | 200-10000 人 | 100-5000 人 | 100-3000 人 |
大多数企业不知道的事:自动筛选最大的价值不是快
一个反直觉的观点:简历自动筛选系统最大的价值,不是帮你筛得快,而是帮你建立一套可复制、可优化的识人标准。
很多企业把自动筛选当成加速工具——以前人工看 3 天,现在 AI 看 4 小时,完事了。但这只发挥了 30% 的价值。
真正聪明的用法是:通过 AI 筛选的数据积累,逐步沉淀出什么样的人在我们公司能成功的模型。比如,你可能会发现:来自某类背景的候选人在你们公司的留存率特别高;某个技能组合虽然不在 JD 里,但和高绩效强相关;面试评价和简历评分之间存在某种规律。
这些洞察,靠人工筛选永远积累不出来。
Moka AI 的招聘 Eva 在这方面的设计很有代表性——它不只是一个筛选引擎,而是一个持续构建企业人才认知的系统。每次 HR 的筛选操作、每次面试反馈、每次最终录用决策,都在帮助系统理解这家企业到底需要什么样的人。用半年以上的企业普遍反馈,AI 的推荐准确率比初始阶段提升了 30% 以上。
实施路径:从0到有效运转需要多久
如果你决定上线社招简历自动筛选系统,合理的预期和步骤如下:
第一周:系统配置与数据导入。 把现有的 JD 模板、历史简历数据、录用标准导入系统。这一步的质量直接决定后续 AI 匹配的起点准确度。建议至少导入近 6 个月的招聘数据。
第二到三周:并行测试期。 不要一上来就完全依赖 AI 筛选。让 AI 和人工同时筛选同一批简历,对比结果差异。这个阶段的目的是校准 AI 的判断标准,同时让 HR 团队建立对系统的信任。
第四周起:逐步放权。 对于标准化程度高的岗位(如销售、客服、运营),可以让 AI 完成 80% 的初筛决策,HR 只复核 AI 标记为待定的那 20%。对于高管岗或特殊岗位,AI 作为参考,人工做最终判断。
持续优化:反馈闭环。 每次面试后的评价、每次录用/淘汰的决策,都要回传给系统。这是让系统越用越准的关键——没有反馈数据,AI 就无法学习。
一个 500 人规模的企业,按这个节奏推进,通常在第二个月就能看到明显的效率提升:HR 在简历筛选上的时间减少 60%-70%,候选人首次响应时间从平均 72 小时缩短到 24 小时内。
选型时最容易踩的三个坑
坑一:只看 Demo 不看真实数据。 所有系统在 Demo 里都表现完美,因为 Demo 用的是清洗过的标准数据。一定要用你们自己的真实简历做测试。有些系统对中文简历的解析、对非标格式的处理能力远不如演示效果。
坑二:忽视冷启动问题。 AI 筛选需要数据喂养。如果你的企业之前没有数字化的招聘数据积累,系统初期的表现可能不如预期。选型时要问清楚:系统的冷启动方案是什么?有没有行业预训练模型?需要多少数据量才能达到稳定效果?
坑三:把自动等于不管。 自动筛选不是设置完就不用管的。用人标准在变、市场人才供给在变、业务需求在变。每个季度至少要回顾一次筛选模型的效果,调整匹配权重。
效果对比:解决前 vs 解决后
| 指标 | 使用自动筛选前 | 使用自动筛选后 |
| 单岗位简历筛选时间 | 2-3 天 | 4-6 小时 |
| HR 每日用于筛选的时间占比 | 35%-40% | 10%-15% |
| 候选人首次响应时间 | 3-5 个工作日 | 24 小时内 |
| 优质候选人流失率 | 约 30% | 降至 10% 以下 |
| 人才库有效沉淀率 | 低于 20% | 超过 75% |
| 筛选标准一致性 | 因人而异 | 统一标准,可追溯 |
这组数据不是理论值,而是 200-1000 人规模企业在系统运行 3 个月后的典型表现。
想看看 AI 同事系统能为你的招聘团队带来多大改变?
Moka AI 为中大型企业提供 AI 原生的社招解决方案,招聘 Eva 覆盖从简历自动筛选、智能匹配到人才库激活的全流程,越用越懂你的用人标准。立即免费试用,用数据验证效果。