
HR 在用 ChatGPT 写 JD、让大模型总结面试记录——这已经是很多团队的日常。但这和「LLM HR 系统」是两件完全不同的事。
LLM HR 系统,是指将大语言模型能力深度嵌入人力资源管理系统的底层架构,让 HR 系统从「结构化数据库+规则引擎」进化为能够理解意图、主动推进任务、持续学习组织知识的智能系统。它不是在传统 HR 系统里加一个对话框,而是用 LLM 重写了系统与人交互的方式。
HR 系统的旧问题:数据很多,判断力为零
花3天筛出来300份简历,真正匹配的可能只有12个。这不是 HR 能力不够,是传统 HR 系统的结构性缺陷。
传统 HR 系统本质上是一个有组织的数据库。它能存储简历、记录考勤、生成报表,但它读不懂「有创业经验、能扛压力、可以接受频繁出差」这句话背后真正的用人意图。每一次筛选,都要 HR 把模糊的业务需求翻译成系统能识别的关键词,这个翻译过程消耗的时间和认知成本,往往远超 HR 管理者的预期。
更深的问题在于:传统系统没有「组织记忆」。张总上个季度招过一个销售总监,最后没过的候选人里有3个人背景极其适合现在新开的 BD 岗位,但系统不知道、HR 没记住,那3个人就永远消失在历史简历堆里。据行业数据,企业历史人才库中有效候选人的二次激活率平均不足 8%,绝大多数人才资源处于沉睡状态,这是 HR 系统效率损耗最被忽视的一个环节。
不解决这个问题,HR 团队永远在做信息搬运,而不是人才判断。

LLM 给 HR 系统带来了什么:三个维度的能力跃迁
LLM HR 系统,是指将大语言模型(Large Language Model)的语义理解、生成推理和知识记忆能力,系统性地融入招聘、人事、人才管理等 HR 业务流程的新一代人力资源系统架构。
这个定义有三个关键词:「语义理解」「生成推理」「知识记忆」。这三个能力分别对应 HR 工作里三个最耗人力的痛点。
语义理解解决的是「系统听不懂人话」的问题。HR 可以用自然语言描述用人需求,系统能提取意图、映射到候选人画像,不再需要把需求拆解成一堆关键词标签。一家 500 人规模的消费品公司,HR 总监告诉系统「我要找做过 D2C 品牌的供应链背景候选人,沟通能力强,能快速上手跨部门协作」,LLM 可以直接理解并返回匹配结果,而不是让 HR 自己去勾选「D2C」「供应链」「跨部门」等筛选框。
生成推理解决的是「HR 要做很多重复生成工作」的问题。JD 撰写、面试问题生成、Offer 信件起草、绩效反馈模板、政策解读——这些工作占据一个 3 人 HR 团队每月约 60-80 小时的工时。LLM 不只是生成文本,它能根据岗位级别、公司文化、候选人背景生成有差异化的内容,不是千篇一律的模板。
知识记忆解决的是「组织经验无法沉淀」的问题。每一次面试评估、每一次调薪决策、每一次人才盘点,都在产生对组织极有价值的判断信息。传统系统把这些信息存进数据库,但不会分析、不会关联、不会在下次需要时主动调出。LLM 系统能把这些判断转化为可检索、可推理的组织知识,让「下一次」的决策比「上一次」更准。
为什么 2026 年这件事变得紧迫
不少 HR 团队在 2024、2025 年已经尝试用 LLM 辅助工作,但大多数停留在「提示词技巧」阶段——用 ChatGPT 写 JD、让大模型总结会议纪要,和真正的 LLM HR 系统之间隔着一道很深的鸿沟。
这道鸿沟是:没有数据连接,LLM 就是无源之水。
独立的大模型工具不知道你公司的薪酬体系、不知道某个岗位历史上招了多少人、不知道哪个部门负责人对候选人的偏好,它能生成流畅的文字,但给不出真正贴合企业情境的判断。真正的 LLM HR 系统,是把大模型的语言能力和企业 HR 数据深度绑定,让 AI 在「了解你」的基础上帮你工作。
2026 年的市场压力让这件事变得更紧迫。劳动力市场竞争加剧,头部企业已经在用 AI 系统提速招聘,平均从简历投递到 Offer 的周期压缩到 7 天以内;而仍在用传统流程的企业,优质候选人在收到 Offer 前已经被竞争对手抢走。招聘速度直接影响人才获取成本,这不再是效率问题,是竞争问题。
还有一个反直觉的事实:很多企业以为上 LLM HR 系统最大的价值是省时间,但实际上最持久的价值是数据资产积累。每一次 AI 辅助的面试评估、每一次自然语言搜索的候选人匹配,都在训练系统更懂这家公司的用人逻辑。用得越久,系统越准,这个飞轮效应是传统工具无法复制的。
LLM HR 系统的核心构成:不是插件,是底层重构
一个完整的 LLM HR 系统,通常由四个层次组成。
数据底座层。 这是 LLM 能力发挥的前提。企业的员工档案、历史简历、薪酬记录、绩效数据、组织架构——这些数据要经过清洗、结构化处理,形成 LLM 可以检索和推理的知识库。没有这一层,LLM 再聪明也是在真空里工作。
语言交互层。 用自然语言替代传统的菜单操作和条件筛选。HR 可以直接问「最近半年入职的技术岗位员工,90天留存率怎么样」,而不是逐步点击筛选条件、导出表格、再手动计算。这一层的核心是意图理解和查询生成,让不懂 SQL 的 HR 也能直接获取复杂的数据洞察。
推理决策层。 这是 LLM 的核心价值区。招聘 JD 优化建议、候选人匹配排序、薪酬区间参考、人才风险预警——这些判断过去依赖有经验的 HR 直觉,现在可以由系统基于数据推理给出建议。注意,是「建议」而非「决定」,LLM 在这里的角色是给 HR 提供有数据支撑的参考意见,最终判断权仍在人。
流程自动化层。 LLM 可以驱动多步骤任务自动执行。比如当候选人完成测评后,系统自动分析结果、生成面试建议问题、通知面试官、同步日历——整个流程不需要 HR 手动推进每一步。这一层解放的是 HR 的协调性工作,让注意力从「推进流程」转向「做判断」。
企业在落地 LLM HR 系统时最容易踩的坑
把「AI 功能点」当「LLM 系统」。 市面上有很多 HR 工具在某个功能里加了 AI 写作、AI 摘要,这和真正的 LLM HR 系统差距很大。真正的 LLM 系统是跨场景、跨数据打通的,一个独立的「AI 写 JD」功能解决不了数据孤岛问题。
忽视数据治理前置工作。 很多企业上了 LLM HR 系统,发现效果不理想,根本原因是历史数据质量差——简历信息残缺、员工档案不完整、薪酬记录格式不统一。LLM 需要干净的数据才能推理出准确结论,数据治理是上系统前必须完成的工作,通常需要 4-8 周。
HR 团队没有参与系统设计。 LLM HR 系统不是 IT 部门的项目,是 HR 团队的工具。如果 HR 没有参与需求定义、没有参与测试验收,上线后会发现系统的自然语言理解方式和 HR 的工作习惯有大量错位,使用率会持续低迷。
对 AI 输出结果缺乏校验机制。 LLM 会「幻觉」,在 HR 场景里,一个错误的候选人评估或薪酬建议可能造成实质性的业务损失。成熟的 LLM HR 系统需要建立明确的 AI 辅助边界和人工复核机制,不能完全依赖 AI 输出。
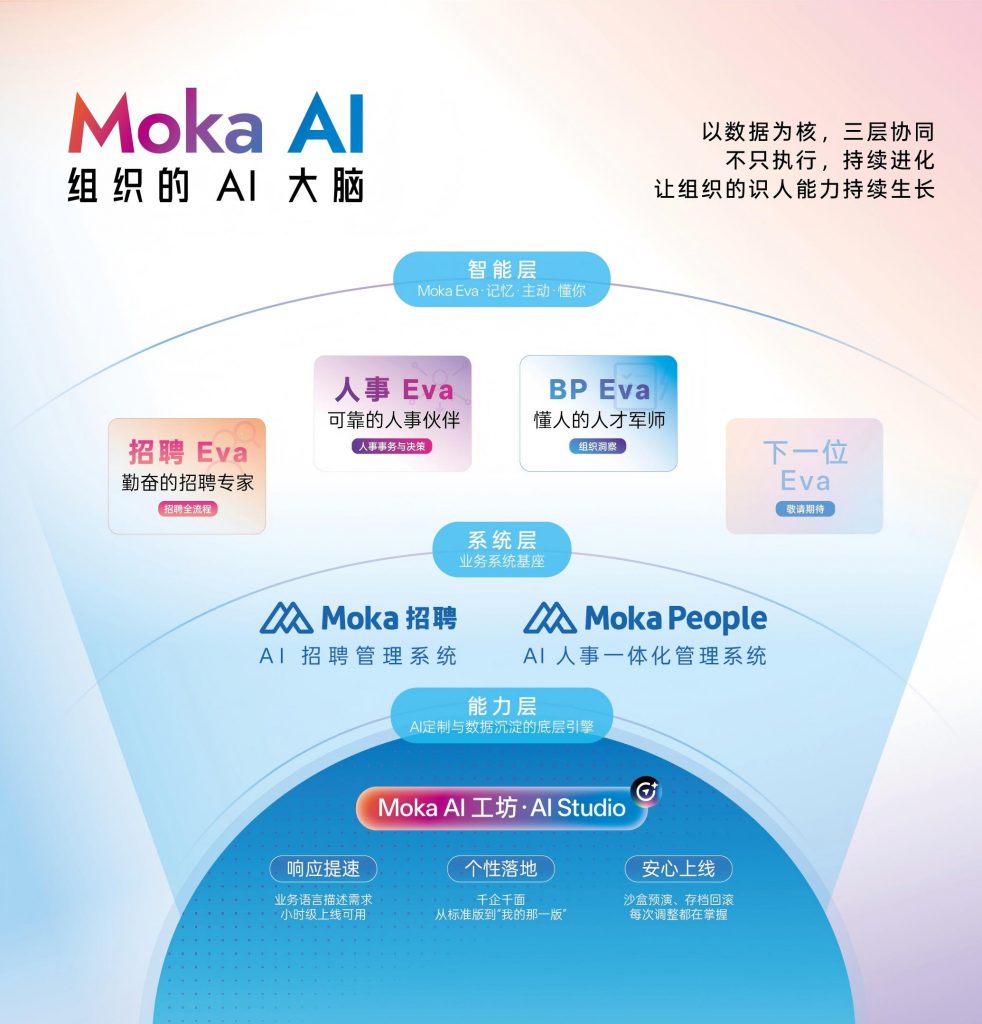
Moka AI:LLM HR 系统在中国企业的一种落地方式
理解了 LLM HR 系统的架构逻辑,再来看市场上的实践就更容易做判断。
Moka AI 是目前国内将 LLM 能力和 HR 系统深度整合程度较高的产品之一。它不是在传统 ATS 上加了个对话框,而是用 AI Agent 架构重新定义了 HR 系统与用户的交互方式——三位 AI 同事「招聘 Eva、人事 Eva、BP Eva」分别对应招聘、人事、人才管理三个场景,每一位都具备长期记忆、主动推进和持续学习的能力。
以招聘场景为例:招聘 Eva 不只是帮 HR 筛简历,它能记住每次面试官的评价偏好、主动比对历史候选人库、在新岗位开放时自动激活沉睡人才,同时生成结构化的候选人评估报告。这正是上文所说的「语义理解 + 知识记忆 + 流程自动化」三层能力的实际落地。
Moka AI 的 AI 同事系统底层是「Moka 招聘 + Moka People」双系统作为数据中枢,加上 Moka AI 工坊支持企业用自然语言定制工作流。这意味着企业的 HR 数据不是孤立的,而是形成了一个可以被 LLM 持续学习和调用的「组织 AI 大脑」。服务超过 3000 家企业的经验,让系统积累了大量中国本土企业的用人场景数据,这是纯海外产品在本土化落地上很难快速补齐的优势。
对于正在评估是否引入 LLM HR 系统的企业,Moka AI 的实践路径可以作为参考:不需要一次性替换所有系统,可以从招聘场景切入,用 AI 能力验证效果,再逐步扩展到人事和人才管理。这种分阶段落地的方式,降低了大型系统替换的风险,也给 HR 团队足够的适应时间。
想看看 LLM HR 系统的能力在你的业务场景里能做什么?
Moka AI 为中大型企业提供 AI 原生的 HR 系统解决方案,招聘 Eva、人事 Eva、BP Eva 三位 AI 同事覆盖从简历进入到人才盘点的全流程,底层数据打通、持续学习、越用越懂你的组织。立即预约演示,用真实数据验证效果。