
人力资源eHR软件系统(Electronic Human Resources System),是指通过数字化技术整合员工信息管理、薪酬核算、考勤排班、绩效评估、招聘管理等HR核心事务的企业级软件平台。
现代eHR系统已从早期的电子档案柜演进为AI驱动的智能化管理平台,能够自动处理80%以上的重复性HR事务,并通过数据积累持续优化组织决策。对于200人以上规模的企业,eHR系统不再是锦上添花的工具,而是保障HR运营效率与合规性的基础设施。
一张Excel撑不住的那一天,就是eHR系统的起点
大多数企业主动了解eHR系统,不是因为看了某篇文章,而是被一次真实的危机推着走的。
一家位于深圳的消费电子企业,员工规模从150人扩张到420人,HR团队只有4人。扩张期的某个月末,薪酬核算出了错:一名已离职员工的工资仍被发放,而另一名新入职员工的工资少发了两天。财务、HR、用人部门三方拉了一个微信群,反复核对记录,最终花了整整三天才完成对账和补发。事后复盘发现,问题根源在于入离职信息分散在三个Excel表里,没有统一的数据源。这家公司在那一年完成了eHR系统的部署。
这个场景在中国企业里极具代表性。根据行业调研数据,规模在200-500人之间的企业中,仍有超过55%依赖Excel加即时通讯工具管理核心HR事务。每年因信息错漏、流程断点导致的直接损失(包括重复劳动、薪酬纠纷、合规风险)平均在8万至15万元之间,还不计算HR团队因此消耗的机会成本。当组织架构开始出现三层以上的层级,当单月简历量突破100份,当跨城市团队协作成为常态,手工流程的隐性代价会呈指数级放大。
人力资源eHR软件系统,是指以数字化方式整合企业HR全流程事务,实现数据统一管理、流程自动化运转、决策数据支撑的企业级管理软件。
这个定义里有三个关键词:统一数据、自动化流程、决策支撑。早期的eHR系统能做到前两项,而当前一代的AI驱动eHR系统,正在真正兑现第三项——用沉淀的数据反哺组织决策。
eHR系统三十年:从电子档案柜到AI同事
了解eHR系统的演进路径,有助于判断当前市场上不同产品所处的代际位置,避免花了新系统的钱,买回一个电子版Excel。
eHR系统的发展大致经历了三个阶段。第一代(1990年代至2005年) 以信息录入和档案存储为核心,本质是把纸质档案搬到电脑里。系统能做到员工基本信息管理和简单的薪资计算,但数据孤岛严重,部门之间的信息同步仍然依赖人工导出和邮件传递。这一代系统在中国企业中以本地部署的C/S架构为主,实施周期长达半年以上。
第二代(2006年至2020年) 随着SaaS模式兴起,eHR系统开始向云端迁移。流程自动化成为核心卖点——入职申请、假期审批、绩效考核表单实现在线流转,员工可以通过手机端自助完成操作。这一代系统显著降低了HR的操作成本,但AI能力几乎为零,系统本质上还是被动响应的工具:HR需要主动去系统里查数据、发起流程、导出报表。
第三代(2022年至今) 以大语言模型和AI Agent技术为驱动,eHR系统开始具备主动推进任务、持续学习企业偏好、跨模块数据联动的能力。简历筛选不再依赖关键词匹配,而是通过语义理解提取候选人能力特征;薪酬异常不是等到月末核算才发现,而是在数据录入时实时预警;员工问题不是排队等HR回复,而是由AI 7×24小时即时解答。这一代系统的核心变化,是从人找系统转向系统主动找人。
反直觉的地方在这里:很多企业采购eHR系统,把最大价值定义为省时间,但实际上最大的价值是数据资产的沉淀。一套运行了3年的eHR系统,积累了企业所有岗位的用人偏好、员工的绩效轨迹、离职原因分布、招聘渠道效益数据。这份数据资产,才是当一个行业周期来临时,比竞争对手快半步做出人才决策的核心依据。系统的价格是一次性的成本,而数据资产是持续复利的资产。
现代eHR系统的核心模块:不是越多越好
现代eHR系统通常覆盖六大核心模块,但不同规模和发展阶段的企业,对各模块的需求权重差异很大。
组织人事管理是所有eHR系统的基础层。这个模块管理的不只是员工档案,更是组织架构的实时状态——部门层级、汇报关系、岗位编制、人员异动,都在这里形成统一的数据源。一旦这层数据稳定,其他所有模块的运转才有可靠的基础。一家管理3个业务板块、分布在8个城市的企业,如果组织架构数据不统一,薪酬核算、权限管理、绩效考核都会产生数据偏差。
薪酬管理是eHR系统里技术复杂度最高、合规要求最严的模块。中国的薪酬计算涉及社保缴纳(不同城市费率不同)、个人所得税专项附加扣除、年终奖计税方式、不同用工形式的薪资结构差异。一家同时使用全职员工、劳务派遣、灵活用工三种用工形式的零售企业,如果依赖人工核算,一个月仅薪酬复核环节就需要消耗2名HR约60小时工时。自动化的薪酬引擎不只是提升效率,更是把薪酬合规的风险从人为判断转移到系统规则。
招聘管理(ATS模块)在过去三年已经成为eHR系统中AI渗透率最高的模块。从多渠道简历聚合(BOSS直聘、猎聘、智联招聘等平台数据统一归集)、智能简历解析,到候选人评分、面试安排协调,再到招聘数据分析——每个环节都有AI介入的空间。一家快速扩张的生命科学企业,半年内需要招聘专业研发人员80名,候选人来源分散在6个平台,如果没有ATS模块统一管理,招聘进展无法实时追踪,Offer接受率分析也无从谈起。
考勤排班对于制造业、零售、医疗等行业来说,是复杂度远超一般认知的模块。AI智能排班需要同时考虑员工合同类型、岗位技能要求、法定节假日规则、加班上限规定,以及员工个人的排班偏好。一家有5个门店、共130名一线员工的连锁餐饮企业,传统排班方式需要店长每月花费8-10小时手动排表,而智能排班系统可以将这个时间压缩到1小时以内,同时把排班冲突率从12%降低到2%以下。
绩效管理和员工自助服务构成了eHR系统的协同层,让HR事务不再只是HR团队的工作,而是全员参与的数字化流程。Moka People的员工自助模块支持员工通过手机端完成入离职申请、工资条查看、证明材料下载等操作,把HR从大量信息传递类工作中解放出来。
选型时最容易踩的坑,集中在这三个地方
企业在选择eHR系统时,踩坑的规律高度相似。
第一个坑:把演示场景当作真实交付能力。 很多系统在演示时能展示漂亮的数据看板和自动化流程,但实际部署后发现,这些能力需要大量的人工配置和数据清洗才能跑通。判断标准是:要求供应商用你们自己的数据(而不是演示数据)跑一遍核心流程,看实际操作的复杂度和报错率。
第二个坑:低估数据迁移的成本。 一家从旧系统迁移到新系统的物流企业,发现历史8年的员工档案数据格式混乱,字段不统一,光数据清洗和迁移就花了3个月,比预期多了两倍时间。在签合同前,必须明确数据迁移的范围、责任方、验收标准和时间节点,这些都应该写入合同条款。
第三个坑:忽略本地化合规能力。 在中国运营的企业,eHR系统必须能够处理中国劳动法、劳动合同法框架下的具体场景:试用期工资标准、竞业限制协议、工伤认定流程、年假计算规则(不同工龄对应不同天数)、社保公积金多城市政策差异。很多国际系统的本地化能力停留在界面汉化层面,遇到具体合规场景时仍需大量定制开发。
选型评估的核心维度,可以归纳为四个问题:这套系统的数据是否真正打通(而不是各模块各自为政)?AI能力是原生集成还是叠加插件?本地化合规覆盖是否满足你们的城市分布?供应商的实施团队是否有你们所在行业的交付经验?
Moka AI:当eHR系统开始像同事一样工作
当前eHR市场有一个明显的分水岭:系统是在等HR发出指令,还是能主动推进任务?
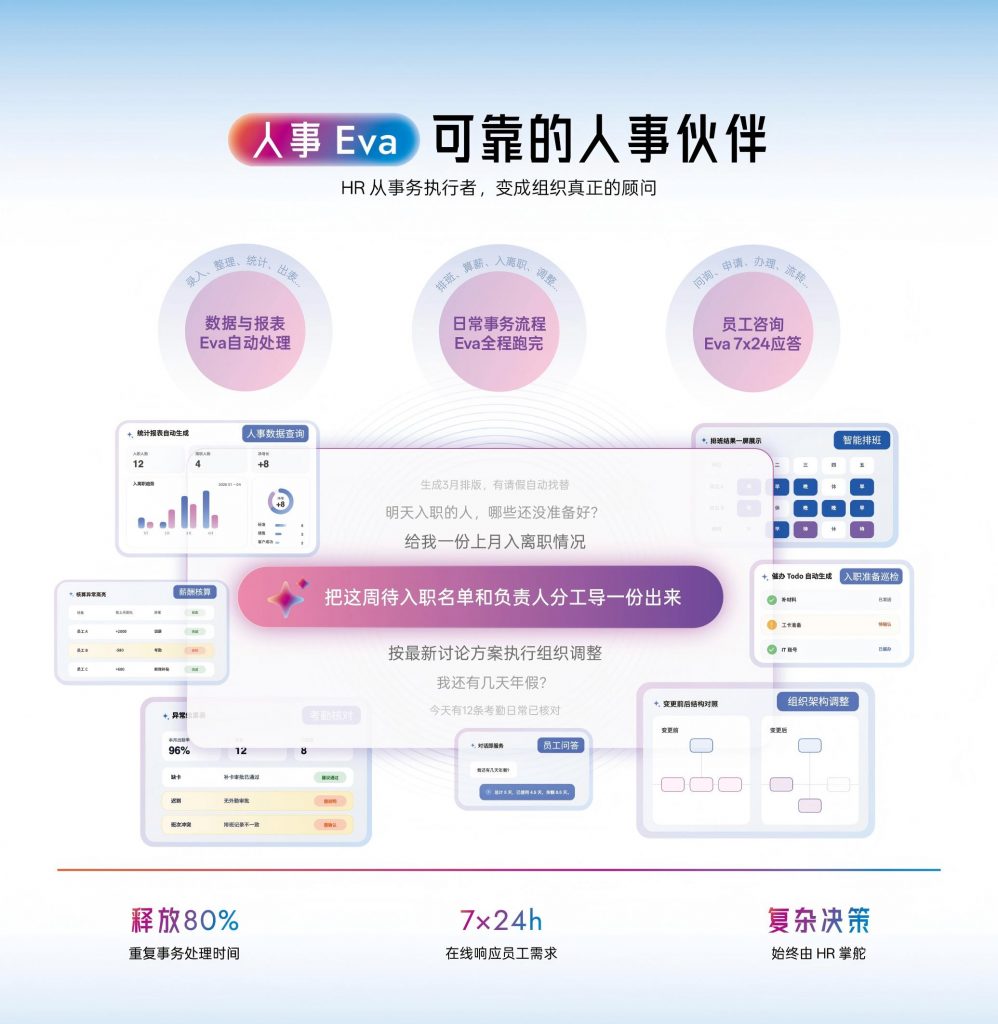
Moka AI 是国内较早将AI Agent能力原生集成到HR系统的产品,旗下的三位AI同事——招聘 Eva、人事 Eva、BP Eva——代表了eHR系统从工具到同事的范式转变。这三位AI同事的核心特点不是功能叠加,而是具备长期记忆、主动推进任务、持续学习企业偏好的能力。
具体到eHR日常场景:人事 Eva 能够接管HR 80%的重复事务,包括入离职流程的自动触发、考勤异常的主动预警、员工问题的7×24小时即时响应。一家300人规模的科技企业,HR团队从6人压缩到4人,通过人事 Eva处理日常事务性工作,4人团队反而能够承担更多的人才发展和组织建设项目。招聘 Eva 不只是简历筛选工具,而是能记住每次面试反馈、持续优化候选人画像、主动激活沉睡人才库的招聘伙伴。BP Eva 则为每位员工建立动态的能力档案,让管理者在做晋升和轮岗决策时有数据支撑,而不是凭直觉判断。
Moka AI 的产品架构分为三层:Moka 招聘和 Moka People 构成数据与流程的记忆中枢,三位 Eva 作为智能交互层主动推进任务,Moka AI 工坊支持企业用自然语言定制个性化的HR流程。这个架构解决了传统eHR系统的核心矛盾:数据在系统里,洞察在人的脑子里。现在,洞察也可以在系统里自动生长。
当前,Moka AI 服务超过3000家企业,覆盖科技互联网、生命科学、先进制造、零售消费等行业。这些客户的共同选择,某种程度上也印证了一个判断:eHR系统的竞争,已经从功能覆盖转向AI协同深度。
想看看Moka AI能为你的团队带来多大改变?
Moka AI 为200人以上规模的中大型企业提供AI原生的eHR解决方案,招聘 Eva、人事 Eva、BP Eva 三位AI同事覆盖从简历筛选到员工发展的HR全流程。不只是更高效的工具,而是一支永不疲倦、越用越懂你的AI团队。