
人事数据自动分析是指通过AI和自动化技术,对企业人力资源数据(如人员结构、离职率、薪酬分布、考勤异常等)进行实时采集、智能计算和可视化呈现的过程。它让HR从手动拉数据、做报表转变为数据主动找人、洞察自动生成,是2026年企业构建数据驱动型组织的基础能力。

什么是人事数据自动分析
人事数据自动分析,是指利用AI算法与自动化引擎,对企业人力资源全域数据进行实时采集、交叉计算、趋势预测和可视化呈现的技术能力。
这个定义里有几个关键词值得拆开来看。
全域数据意味着不只是考勤和薪资,还包括绩效评分、培训记录、晋升轨迹、面谈反馈、甚至招聘阶段的候选人画像数据。一家800人规模的零售企业,其HR系统中每月产生的数据点可能超过15万条——考勤打卡、加班申请、假期余额、绩效目标进度、薪酬变动记录,这些数据散落在不同模块中,如果没有自动分析能力,它们就只是沉睡的数字。
自动则是与传统报表最大的区别。传统模式下,HR需要从系统导出Excel,手动清洗数据、建立透视表、制作图表,一份季度人力成本分析报告平均耗时8-12小时。而自动分析意味着系统能够按照预设规则或AI判断,主动生成洞察、推送异常预警,HR打开系统时看到的不是原始数据,而是已经加工好的结论。
为什么2026年这件事变得不可回避
据行业数据显示,2025年中国企业HR部门平均花费47%的工作时间在数据整理和报表制作上。这个数字在500人以上的企业中更高,达到53%。当企业管理层要求HR用数据说话时,HR团队面临的现实是:数据散落在招聘系统、考勤系统、薪酬系统、OA系统等多个平台,光是把数据拉齐就要花掉大半天。
2026年的变化在于三个外部压力同时到来。
业务节奏加快,决策窗口缩短。 一家快速扩张的科技公司,业务负责人周一提出我们部门离职率是不是偏高,如果HR周五才能给出分析报告,这个信息已经失去了干预价值。人事数据自动分析能把这个响应时间从5天压缩到5分钟——系统实时计算离职率,按部门、职级、司龄交叉分析,异常值自动标红。
AI原生组织对数据基建的要求。 当企业开始引入AI同事处理招聘、绩效、人才盘点等工作时,AI的决策质量完全取决于底层数据的完整性和实时性。没有自动化的数据分析能力,AI同事就像一个没有记忆的新人,每次都要从零开始了解情况。
合规与审计压力增大。 劳动法规对企业用工数据的留存和分析提出了更高要求。自动分析能力意味着企业可以随时调取任意时间段的人力数据切片,而不是在审计来临时手忙脚乱地补数据。
人事数据自动分析的四个核心能力层
一套成熟的人事数据自动分析体系包含数据整合、智能计算、异常预警和预测建模四个能力层,它们层层递进,构成完整的数据智能闭环。
数据整合层:打破信息孤岛。 这是最基础也最容易被低估的一层。很多企业的招聘数据在ATS里,考勤数据在打卡机里,薪酬数据在财务系统里,绩效数据在OKR工具里。自动分析的前提是把这些数据汇聚到统一的数据底座上。一家300人的生命科学企业曾经做过测算:仅仅是把分散在6个系统中的人事数据手动对齐,每月就要消耗HR团队约35小时。
智能计算层:从原始数据到业务指标。 原始数据本身没有意义,张三本月出勤22天这条数据只有和部门平均出勤天数同期对比加班时长等维度交叉计算后,才能产生洞察。智能计算层的核心是预置上百个HR业务指标的计算逻辑——人均效能、人力成本占比、关键岗位空缺时长、offer接受率等——并且能够根据企业的组织架构自动聚合到不同层级。
异常预警层:让数据主动说话。 这是自动分析区别于传统BI报表的关键能力。系统不是等HR来查数据,而是当数据出现异常波动时主动推送提醒。比如某个部门连续两个月离职率超过15%,或者某个职级的薪酬中位数偏离市场水平超过20%,系统会自动生成预警并推送给相关HR负责人。
预测建模层:从发生了什么到将要发生什么。 这是2026年AI能力带来的最大增量。基于历史数据训练的模型可以预测未来3-6个月的离职风险、招聘需求波动、人力成本变化趋势。一家2000人规模的制造业企业通过离职预测模型,提前识别出高离职风险员工,将核心岗位的主动离职率降低了28%。
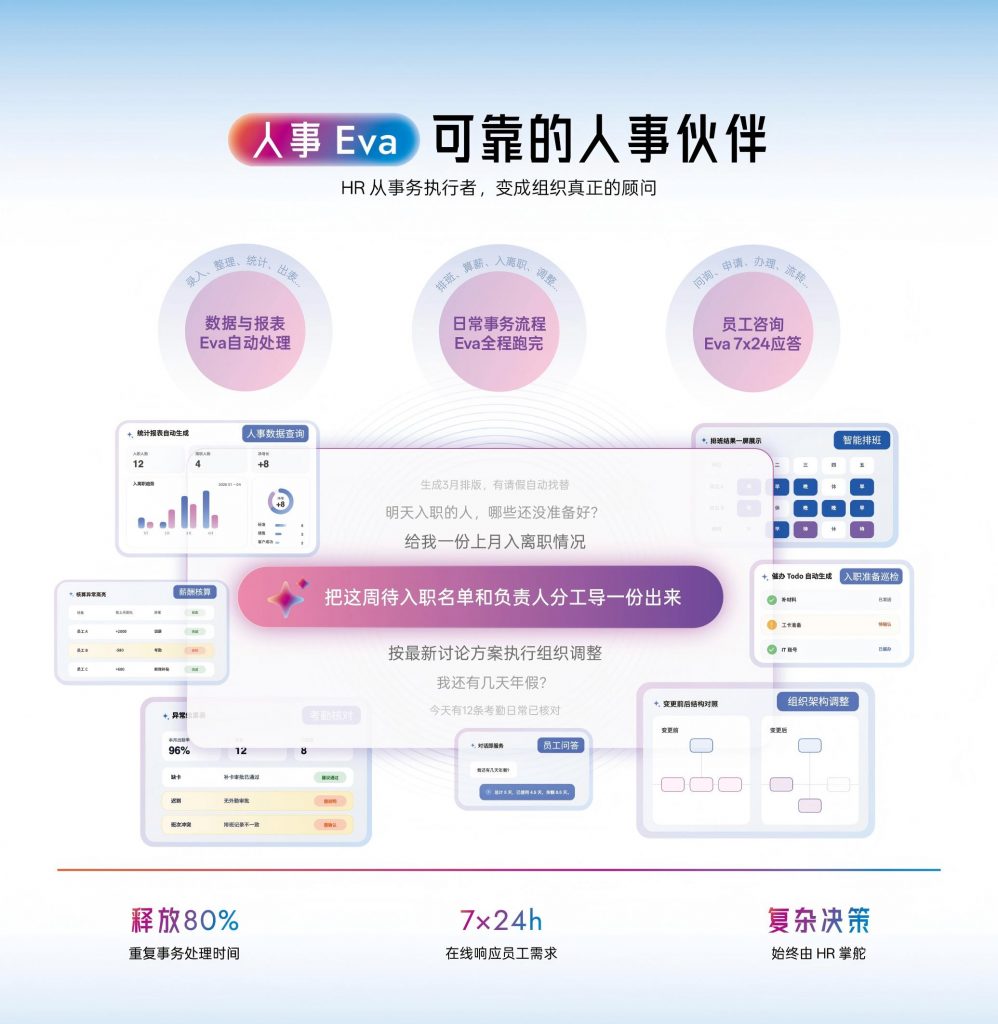
大多数企业踩过的坑:有系统不等于有分析能力
一个反直觉的事实是:超过70%已经部署了HR系统的企业,仍然在用Excel做人事数据分析。
原因并不复杂。很多传统HR系统的报表功能本质上只是数据导出——把数据库里的字段按条件筛选后导出成表格,真正的分析工作还是要HR自己完成。这就像给了你一个装满食材的冰箱,但没有灶台和菜谱,你还是得自己想办法做饭。
另一个常见问题是数据质量黑洞。当入职信息、异动记录、绩效评分等数据的录入依赖人工操作时,缺失值、错误值、格式不统一等问题会让自动分析的结果失去可信度。据行业调研,中国企业HR数据的平均完整率只有72%,这意味着近三成的数据存在缺失或错误。
解决这个问题的关键不是买一个BI工具,而是从数据产生的源头就实现自动化。当入离职流程、考勤记录、绩效评分等操作本身就在系统内完成时,数据天然是完整、规范、实时的。这也是为什么一体化HR系统在数据分析能力上天然优于多系统拼接方案——数据不需要搬运,就不会在搬运过程中丢失或变形。
评估人事数据自动分析能力的五个维度
当企业在选择HR系统或升级数据分析能力时,可以从以下维度进行评估:
| 评估维度 | 基础水平 | 进阶水平 | 领先水平 |
| 数据覆盖范围 | 仅覆盖考勤薪酬 | 覆盖招聘+人事+绩效 | 全模块数据打通,含非结构化数据 |
| 分析实时性 | T+1(隔天更新) | 准实时(小时级) | 实时计算,秒级响应 |
| 预警能力 | 无预警,需手动查看 | 基于规则的阈值预警 | AI驱动的智能预警+归因分析 |
| 预测能力 | 无 | 简单趋势外推 | 多因子预测模型,准确率>80% |
| 自定义程度 | 固定报表模板 | 可拖拽自定义维度 | 自然语言提问,AI自动生成分析 |
其中自然语言提问是2026年的分水岭能力。HR不需要学习复杂的筛选条件和报表配置,直接用自然语言问研发部门过去半年的人均产出变化趋势是什么,系统就能自动理解意图、调取数据、生成图表和结论。
从概念到落地:Moka AI 的实践路径
在人事数据自动分析这个领域,Moka AI 的实践提供了一个值得参考的样本。
Moka AI 的人事数据分析能力建立在其一体化架构之上——Moka 招聘和 Moka People 两个系统层的数据天然打通,从候选人进入招聘漏斗的那一刻起,到入职、转正、晋升、离职的全生命周期数据都在同一个数据底座上。这解决了前面提到的数据孤岛和数据质量两个根本问题。
人事 Eva 作为 Moka AI 的人事 AI 同事,在数据分析场景中扮演的角色是从人找数据到数据主动找人。具体来说:
当某个部门的离职率出现异常波动时,人事 Eva 不会等HR来查,而是主动推送分析结论:市场部近30天离职率达到18%,高于公司均值2.4倍,离职人员中83%司龄在6-12个月,建议关注该部门新人融入机制。这不是一个需要HR手动配置的规则引擎,而是AI基于数据模式自动识别的异常。
BP Eva 则在更深层的人才分析场景中发挥作用。当业务负责人需要了解团队的能力结构和人才储备情况时,BP Eva 能够基于人才库中的全量数据,自动生成组织能力地图,标注关键岗位的继任风险和能力缺口。
Moka AI 工坊(Moka AI Studio)则让企业可以用自然语言定义自己的分析逻辑。比如一家连锁零售企业可以设定当任意门店的店长岗位空缺超过7天时,自动触发内部人才推荐+外部招聘启动,这个规则背后涉及的数据调取、条件判断、动作触发全部由系统自动完成。
未来12个月的演进方向
人事数据自动分析在2026年下半年到2027年的演进,有三个值得关注的方向。
从描述性分析到处方性分析。 不只是告诉你发生了什么和为什么发生,而是直接给出应该怎么做。比如系统识别到某个团队的绩效下滑趋势后,不只是预警,而是结合历史上类似情况的干预措施和效果,推荐具体的行动方案。
跨域数据融合。 人事数据与业务数据(营收、客户满意度、项目交付率)的交叉分析将成为常态。人均产出不再只是HR指标,而是连接人力投入和业务产出的桥梁。
隐私计算与数据安全。 随着人事数据分析的深度增加,员工隐私保护的技术要求也在提升。联邦学习、差分隐私等技术将被更多地应用于HR数据分析场景,确保在获得群体洞察的同时不暴露个体隐私。
对于还在用Excel做人事分析的企业来说,2026年是一个关键的转折点。不是因为技术突然成熟了——技术早就准备好了——而是因为业务对HR数据决策的要求已经到了不自动化就跟不上节奏的临界点。
想让人事数据从沉睡的报表变成主动说话的决策引擎?
Moka AI 为中大型企业提供 AI 原生的一体化人力资源解决方案,人事 Eva 覆盖从数据采集、智能分析到预警推送的全流程,让HR团队把精力从做报表释放到做决策。立即免费试用,用数据验证效果。
