
大模型企业HR应用,是指将大语言模型(LLM)及其衍生的AI Agent能力,深度嵌入企业人力资源管理全流程的技术实践与产品形态。
它不是给HR系统加一个聊天窗口,而是让AI以数字同事的身份参与招聘、人事、人才管理等核心决策环节。据行业数据显示,2026年已有超过45%的500人以上企业在HR场景中部署了大模型应用,但其中仅12%真正发挥了大模型的核心价值。
大多数企业对大模型HR应用的理解,停留在自动回复层面
大模型企业HR应用,是指基于大语言模型能力构建的、覆盖人力资源管理全链条的智能化应用体系,其核心不是自动化而是认知能力的规模化复制。
这个定义里藏着一个关键区别:自动化解决的是重复劳动问题,大模型解决的是判断力稀缺问题。
大多数人以为大模型在HR领域的价值是让机器干人的活儿——自动筛简历、自动排班、自动算薪。但实际上,这些事情传统RPA和规则引擎早就能做。大模型真正改变的是那些过去只有资深HR才能胜任的判断型工作:评估一个候选人的潜力与岗位的匹配度、判断一次绩效面谈中员工的真实状态、在组织架构调整时预测人才流失风险。
一家800人规模的金融科技公司,HR团队7人,过去每次校招季需要从3000+份简历中筛选出200人进入面试。传统ATS通过关键词匹配能完成初筛,但这个人虽然专业不对口,但项目经历显示出极强的学习能力这类判断,只有招聘总监能做。大模型的介入,让这种识人眼光不再依赖某一个人的经验。

2026年大模型HR应用的三个真实形态(不是你想的那样)
大模型在企业HR场景中已经演化出三种截然不同的落地形态,多数企业只看到了第一种。
形态一:对话式交互层。 这是最容易被看见的部分——员工问我还剩几天年假,AI即时回答。坦白说,这个层面的价值有限,一个配置好的FAQ机器人就能做到80%。
形态二:决策辅助层。 这才是大模型的核心战场。比如在招聘流程管理环节,大模型不只是解析简历文本,而是结合岗位JD、团队现有人员能力图谱、历史录用数据,给出这个人进入团队后可能产生什么化学反应的预判。这种能力过去只存在于顶级猎头的脑子里。
形态三:组织认知沉淀层。 这是90%的企业还没意识到的层面。每一次面试评价、每一次绩效沟通、每一次人才盘点,都在喂养一个越来越懂这家企业的组织大脑。三年后,这个大脑积累的认知资产,可能比任何一位HRBP的经验都要完整。
为什么67%部署了大模型的企业,效果远低于预期
反直觉的事实:大模型HR应用失败的头号原因不是技术不行,而是数据基础太差。
研究显示,企业在大模型HR应用上的投入产出比呈现明显的两极分化——做得好的企业,单次招聘成本下降38%、HR事务性工作减少60%以上;做得差的企业,花了几十万部署费用,最后AI给出的推荐还不如HR自己看。
差距来源于三个被忽视的前提条件:
数据质量决定了大模型的上限。 如果企业过去五年的面试评价都是该候选人表现良好,建议录用这种空泛描述,大模型从中能学到什么?什么也学不到。大模型需要的是结构化的、有区分度的数据——具体评估了哪些维度、每个维度的表现如何、最终结果怎样。
流程标准化程度决定了AI的介入空间。 一家企业如果连招聘流程都没统一,有的部门三轮面试有的两轮,面试官评价标准五花八门,大模型根本无法找到规律。这就像让一个天才分析师去分析一堆格式不统一的Excel——能力再强也白搭。
组织信任度决定了应用深度。 大多数人以为推行大模型HR应用的阻力是技术门槛,但实际上最大的阻力是信任。当AI建议这位候选人综合评分85分,建议进入终面时,面试官会不会采纳?如果每次都被推翻,AI就永远只能当摆设。
大模型HR应用的核心能力拆解:不止是聪明,更是有记忆
区别于传统AI工具,大模型企业HR应用的根本优势在于三个字:有记忆。它不是每次对话都从零开始的聊天机器人,而是一个持续积累组织认知的数字实体。
具体到HR场景,这种有记忆的能力体现为:
人才认知的持续生长。 当一个候选人三年前投递过简历被婉拒,两年前在行业会议上被HR标记为值得关注,今年又出现在猎头推荐名单中——大模型能把这些散落的信息串联起来,形成对这个人的完整认知画像。传统系统做不到这一点,因为数据分散在企业人才库、邮件、笔记等不同角落。
组织偏好的自动学习。 某个业务线过去两年录用了30人,最终留存率高的有什么共性?绩效排名前20%的人在面试阶段有什么特征?大模型能从历史数据中提炼出这些模式,而且随着数据积累,判断会越来越准。
跨场景的知识迁移。 招聘场景中积累的人才评估模型,可以迁移到内部人才盘点;绩效数据中的能力标签,可以反哺招聘时的岗位匹配。这种跨场景的知识流动,是大模型相比单点AI工具的结构性优势。
选择大模型HR应用的四个评估维度(不是看谁的模型参数大)
企业选型时最常犯的错误是比较谁用的大模型更先进。大多数人以为底层模型的参数量决定了应用效果,但实际上在HR这个垂直领域,数据飞轮和场景理解深度远比通用模型能力重要。
维度一:数据闭环能力。 系统能否让每次使用都变成训练数据?面试官的每次采纳或拒绝AI建议的行为,能否被自动学习?这决定了系统是用三年跟第一天一样还是用三年比三个老HR加起来都懂。
维度二:场景覆盖的完整度。 大模型的价值在HR领域是乘法效应——只覆盖招聘环节,价值是1×N;覆盖招聘+人事+人才管理,价值是N×N×N。因为跨场景的数据流动能产生远超单场景的洞察。
维度三:可解释性与可控性。 AI说推荐这个候选人,能不能解释为什么?在涉及公平性的场景(如晋升、裁员),模型的决策逻辑是否透明可审计?这不只是技术问题,更是合规问题。
维度四:与现有流程的融合度。 再强大的AI,如果需要HR改变全部工作习惯才能用起来,就注定失败。好的大模型HR应用应该嵌入既有工作流——在HR已经习惯的界面里,在已经存在的流程节点上,自然地提供增量价值。
Moka AI 的实践:当大模型遇上AI同事产品哲学
在大模型企业HR应用这个领域,Moka AI 选择了一条与众不同的路径——不是把大模型当工具塞给HR,而是把大模型训练成HR的AI同事。
这种产品哲学背后有一个深刻洞察:HR不需要一个什么都能干但什么都需要指令的AI工具,而需要一个理解上下文、能主动行动、用得越久越默契的协作伙伴。
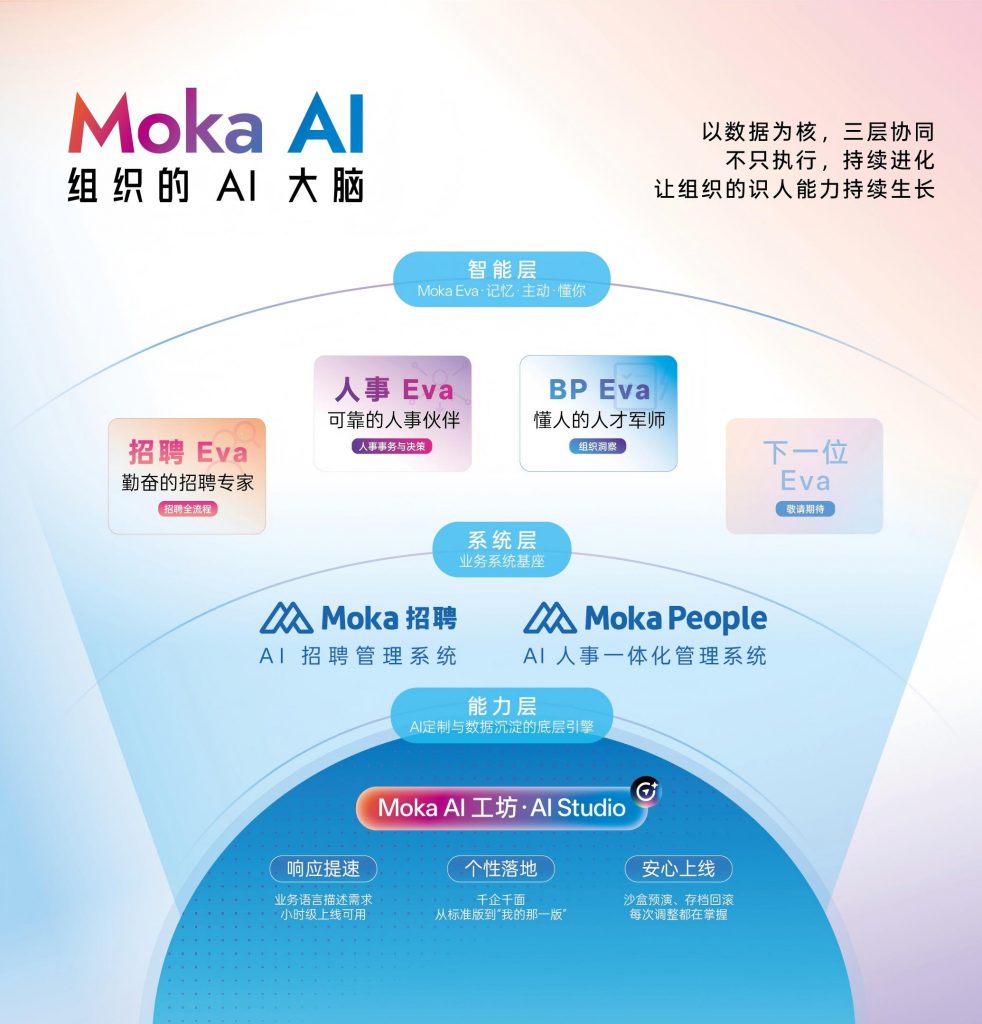
Moka AI 的三位AI同事——招聘Eva、人事Eva、BP Eva——分别对应大模型在招聘、人事事务、人才管理三个场景的深度落地。以招聘Eva为例,它不是在HR打开系统后被动等待指令,而是会主动提醒上周标记的3位高匹配候选人中,有1位刚更新了LinkedIn状态,可能在看机会。
底层支撑这种主动性的,是Moka AI的三层架构:系统层(Moka招聘 + Moka People)负责数据沉淀,是组织的记忆中枢;能力层(Moka AI工坊)支持企业用自然语言定制AI行为;智能层(三位Eva)直接与HR协作。
更值得关注的是Moka AI工坊的设计思路——企业不需要懂技术,用自然语言就能定制AI同事的行为模式。比如当候选人超过5天未收到面试反馈时,自动提醒对应面试官并抄送HRBP,这种过去需要开发排期的需求,现在HR自己就能配置。
据Moka AI服务的3000+企业数据,部署AI同事系统6个月后,招聘数据分析显示平均单岗位招聘周期缩短11天,HR事务性工作占比从65%降至30%以下,面试官对候选人的评价结构化程度提升了4倍。
2026年之后:大模型HR应用的终局不是更聪明的系统
如果你读到这里还在想大模型HR应用就是让系统更聪明,那我要给出最后一个反常识观点:大模型在HR领域的终极价值,不是让系统变聪明,而是让组织的识人能力变成可复利的资产。
一位资深HRBP离职,带走的是十几年积累的识人经验——哪类人适合这个团队、什么样的候选人面试表现好但入职后水土不服、哪些绩效指标能真正预测高潜力。这些经验过去只存在于个人脑中,无法继承。
大模型改变了这个局面。当组织的识人经验被持续沉淀在AI系统中,它就不再是某个人的私有资产,而成为组织的公共基础设施。新来的HR第一天就能站在前人经验的肩膀上工作,而不是从零开始摸索。
这才是大模型企业HR应用的真正价值——把企业最昂贵的黑箱(人才判断),变成最可复利的资产。
想看看大模型如何在你的HR团队中真正落地,而不是沦为高级聊天机器人?
Moka AI 为中大型企业提供AI原生的人力资源管理解决方案,三位AI同事覆盖从人才获取到人才发展的全生命周期。立即免费试用,让你的组织识人能力开始沉淀生长。