
简历管理系统软件是帮助企业集中存储、智能解析、高效检索和协同处理候选人简历的专业数字化工具,核心能力涵盖简历解析、查重去重、标签分类、人才库构建和数据分析。
2026年,随着AI技术深度融入招聘场景,简历管理系统已从单纯的电子文件柜进化为企业人才资产运营的核心基础设施,平均可将HR简历处理效率提升3-5倍。

一个被低估的数据:简历处理占据HR多少工时?
据2026年中国人力资源数字化调研数据,一名全职招聘HR每周平均花费17.6小时在简历相关事务上——包括收集、整理、去重、筛选和归档。这意味着在标准40小时工作周中,44%的时间被简历处理吞噬,而非用在面试评估、候选人沟通等高价值环节。
更令人意外的是,在年招聘量超过500人的企业中,仅简历查重一项工作就平均消耗每月12小时。一份简历从不同渠道重复进入系统的概率高达23%,如果没有自动去重机制,HR团队不得不反复处理同一位候选人的信息。
简历管理系统软件,是指专门用于企业对候选人简历进行集中存储、结构化解析、智能分类和高效检索的软件系统。
这个定义看起来简单,但背后涉及的技术复杂度远超多数人的想象。一份简历可能是PDF、Word、图片甚至邮件正文,格式千差万别;候选人的表述方式各不相同,3年Java开发和Java研发经验三年在系统眼里是完全不同的文本,但对HR来说是同一件事。让机器理解这些差异,就是简历管理系统的核心技术挑战。
从Excel到AI:简历管理经历了哪些阶段?
简历管理系统经历了三个明确的演进阶段,每个阶段解决的核心问题完全不同。
阶段一:手工时代(2015年以前)。 多数企业用Excel或共享文件夹管理简历。据行业回顾数据,这一阶段企业平均简历流失率超过60%——大量候选人信息散落在不同招聘人员的邮箱和桌面,离职即丢失。一家300人的制造企业曾统计,5年内收到的简历只有不到20%能被重新找到。
阶段二:数据库时代(2015-2022年)。 企业开始使用招聘管理系统(ATS),简历被集中存储在数据库中。核心解决了找得到的问题,但解析准确率普遍在70-80%之间,结构化程度有限。HR仍需大量人工校对和补充信息。
阶段三:AI原生时代(2023年至今)。 深度学习模型让简历解析准确率突破95%,语义搜索让找相似背景的人成为可能。简历管理从被动存储变为主动运营——系统不仅能存简历,还能理解简历、推荐人才、预测匹配度。据LinkedIn 2025年发布的全球招聘技术报告,采用AI简历管理的企业,招聘周期平均缩短38%。
简历管理系统的五大核心能力模块
一套成熟的简历管理系统软件通常包含五大核心能力:简历解析引擎、智能去重机制、标签与分类体系、企业人才库构建、以及数据分析看板。
简历解析引擎是整个系统的技术基石。它负责将非结构化的简历文档转化为结构化数据字段——姓名、联系方式、教育背景、工作经历、技能标签等。解析的准确率直接决定后续所有功能的可用性。2026年主流系统的解析准确率在92%-97%之间,顶尖系统可以识别超过120个字段,包括项目经历中的技术栈、管理幅度等深层信息。
智能去重解决的是同一个人多份简历的问题。一位活跃候选人可能通过招聘网站投递一次、猎头推荐一次、内推进入一次,如果没有去重机制,HR会在不同阶段反复处理同一人。优秀的去重算法不仅对比姓名和手机号,还能通过教育经历、工作轨迹等多维度进行模糊匹配,识别率可达98%以上。
标签与分类体系让海量简历从一堆文件变成可运营的资产。系统根据解析结果自动打标签——行业、职能、技能、薪资区间、地域偏好等。HR也可以手动添加业务标签,如已面试-待跟进高潜力-Q3再联系。这套标签体系让人才库从静态档案变成动态的候选人池。
人才库构建是简历管理系统区别于普通文件管理的核心价值。每一份进入系统的简历都不是一次性消耗品,而是企业的长期人才资产。据行业数据,一个运营良好的企业人才库,可以为后续招聘提供30%-40%的候选人来源,显著降低外部渠道采购成本。
数据分析看板将招聘过程中的简历数据转化为决策依据——各渠道简历质量对比、各岗位简历转化漏斗、HR团队处理效率等。这些数据帮助企业持续优化招聘策略,而不是凭感觉做决定。
哪些企业最需要简历管理系统?一组对比数据
并非所有企业都需要专业的简历管理系统,但当招聘规模和复杂度达到临界点时,没有系统支撑的代价会急剧上升。
年招聘量超过100人的企业是最明确的目标用户。以一家500人规模的零售企业为例:全年招聘岗位约80个,累计收到简历超过6000份,HR团队4人。如果用Excel管理,每人每天需要处理约8份简历的录入和筛选工作,仅这一项就占据每天1.5-2小时。而使用简历管理系统后,解析和初筛可以在简历进入的瞬间自动完成,HR只需关注系统推荐的Top候选人。
快速扩张期的科技公司是另一个典型场景。一家互联网公司在半年内需要招聘150人,意味着同时运行50+个招聘需求,每天涌入的简历可能超过100份。没有系统支撑,简历漏看、响应延迟、候选人体验差等问题会集中爆发。据统计,候选人在投递后48小时内未收到反馈,主动放弃的概率增加65%。
多部门协同招聘的企业同样依赖简历管理系统。当用人经理、HRBP、招聘团队需要共同评估候选人时,简历的流转、批注和状态更新必须在统一平台完成。邮件转发简历的方式不仅效率低,还存在数据安全隐患——候选人的隐私信息在邮件链中不可控地扩散。
从投入产出比来看:一套简历管理系统的年费通常在3-15万元(视企业规模),而一名招聘HR的年人力成本在15-25万元。如果系统能节省一名HR 40%的时间,相当于每年为企业释放6-10万元的人力价值,ROI在第一年就能转正。
2026年选型简历管理系统的六个关键维度
选择简历管理系统时,多数企业容易被功能清单迷惑,实际上真正影响使用效果的往往是那些不在宣传页面上的细节。
维度一:解析准确率,而非解析速度。 几乎所有系统都宣称秒级解析,但速度不是瓶颈,准确率才是。建议用企业实际收到的简历样本(包括各种奇怪格式)做测试,关注PDF扫描件、图片简历、非标准排版的识别效果。准确率低于90%的系统,后续人工校对的成本会吃掉自动化带来的效率收益。
维度二:语义搜索能力。 传统关键词搜索只能精确匹配,而语义搜索能理解意图。比如搜索有跨境电商经验的运营,语义搜索能找到简历中写着负责Amazon北美站点日常运营的候选人。这个能力在人才库规模超过5000份简历后,价值会急剧放大。
维度三:渠道整合范围。 一个好的系统应该能对接企业常用的招聘渠道——前程无忧、Boss直聘、猎聘、拉勾等,实现简历自动抓取和归集。手动导入不仅费时,还容易遗漏。对接渠道越多,简历数据越完整。
维度四:协同能力和权限设计。 招聘是多角色协同的过程。系统是否支持用人经理直接在系统内查看简历并反馈意见?是否有精细的权限控制,确保不同角色只能看到该看的信息?这些直接影响跨部门协作效率。
维度五:人才库的长期运营能力。 简历管理不是一次性行为,而是持续积累。系统是否支持候选人状态跟踪?是否能在有新岗位时自动匹配历史候选人?人才库的活化能力决定了这笔数据资产能否产生复利。
维度六:AI能力的深度。 2026年,AI已不是加分项而是必选项。但有AI和AI好用之间差距巨大。需要关注:AI筛选的推荐理由是否可解释?AI学习的周期有多长?能否根据企业自己的用人偏好持续优化?
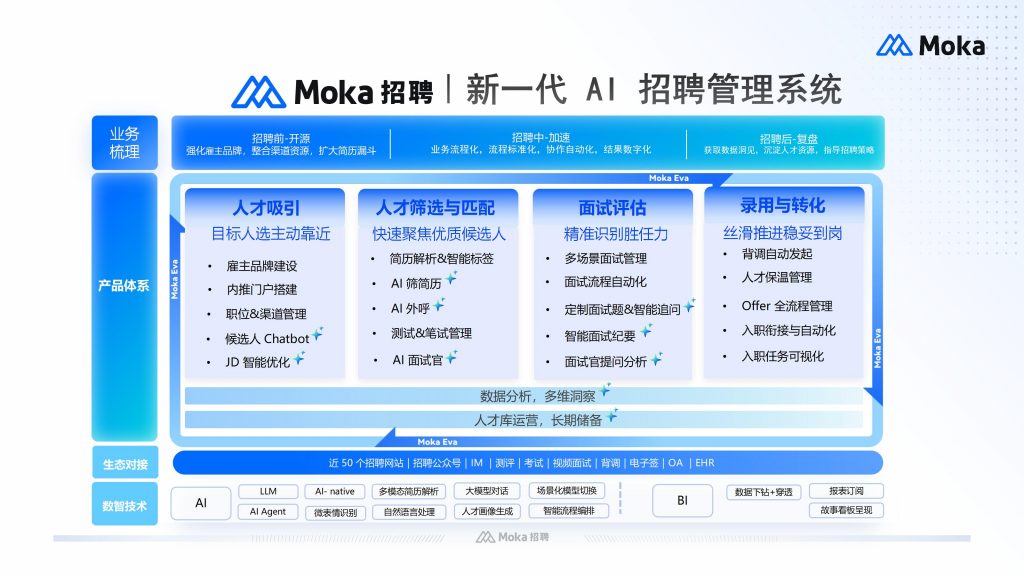
Moka AI 的实践:当简历管理遇到AI同事
在简历管理领域,Moka AI 的招聘 Eva 提供了一个值得参考的实践案例——它把简历管理从工具操作变成了有AI同事帮你干活。
具体体现在几个层面:招聘 Eva 的简历解析引擎基于深度学习模型,对中文简历的字段识别覆盖100+维度,包括项目经历中的技术栈拆解、管理幅度判断等传统系统难以处理的深层信息。在实际测试中,对非标准格式简历(图片、扫描件、创意设计类简历)的解析准确率保持在95%以上。
更关键的是越用越懂你的特性。招聘 Eva 会记住每次HR对候选人的筛选反馈——通过的、拒绝的、犹豫的——持续优化推荐模型。一家使用Moka AI 6个月的金融科技公司反馈,系统推荐的候选人被HR采纳的比例从初期的40%上升到72%,相当于系统越来越理解这家公司到底想要什么样的人。
在人才库运营方面,Moka AI 的人才库支持候选人状态自动更新和休眠激活。当企业新开一个岗位时,系统会自动从历史人才库中匹配可能合适的候选人,推送给招聘HR。据客户数据,这一功能平均为企业提供了35%的候选人来源,直接降低了外部渠道采购费用。

一个容易被忽略的价值:数据资产的复利效应
多数企业把简历管理系统当作提效工具来评估,但实际上它最大的长期价值在于数据资产的积累。
一组数据可以说明这个逻辑:一家年招聘量200人的企业,每年会积累约4000-6000份简历。三年后,人才库中沉淀了超过15000份经过筛选和标注的候选人信息。这些数据的价值不仅是下次招聘时能找到这个人,更在于它构成了企业独有的人才市场认知——什么样的人最终留下来了,什么样的背景在这个岗位上表现最好,什么渠道的候选人质量最高。
这种认知的价值远超系统本身的功能价值。它帮助企业从凭经验招人走向凭数据识人,而且这个数据资产随时间推移只会增值,不会贬值。
没有系统的企业,这些数据散落在各处,人员变动后就彻底丢失。据统计,招聘HR离职后,其积累的候选人关系和判断经验,平均只有不到15%能被继任者继承。简历管理系统本质上是把人的经验沉淀为组织的记忆。
想看看 AI 同事系统能为你的招聘团队带来多大改变?
Moka AI 为中大型企业提供 AI 原生的招聘解决方案,从简历解析、智能筛选到人才库运营,让每一份简历都成为企业的长期人才资产。立即免费试用,用数据验证效果。