
根据2026年中国HR科技行业调研,78%的200人以上企业已经在使用某种形式的AI简历筛选工具,但其中只有23%对筛选效果表示非常满意。
这个巨大的落差揭示了一个事实:市面上AI简历筛选软件数量激增,但企业真正需要的不只是能跑起来的AI,而是能持续学习、越用越准的智能筛选系统。目前主流的AI简历筛选软件包括Moka AI(招聘Eva)、猎聘ATS、智联招聘智能筛选、e成科技、Moka招聘系统等,它们在解析精度、学习能力和场景适配上差异显著。

一组数据揭开AI简历筛选的真实现状
AI简历筛选市场的核心矛盾是:工具数量多,但真正解决问题的少。据行业数据,2026年中国市场上提供AI简历筛选功能的软件超过40款,但企业HR平均只试用过2.3款,最终长期使用的往往只有1款。
为什么会这样?问题出在筛选这个动作本身的复杂度被低估了。
一份简历平均包含15-25个信息字段,但HR在做初筛判断时,真正关注的决策因子通常只有5-8个——而且这5-8个因子在不同岗位、不同业务阶段、不同用人经理偏好下是动态变化的。一个只能做关键词匹配的AI工具和一个能理解岗位上下文的AI系统,筛选准确率差距可达3倍以上。
从投入产出比来看:一家300人规模的企业,HR团队4人,月均处理600份简历。如果用传统方式(人工逐一阅读+Excel记录),每月仅初筛环节就要消耗约80小时。引入AI筛选工具后,这个时间可以压缩到8-12小时——但前提是选对了工具。
2026年主流AI简历筛选软件能力分级
市面上AI简历筛选软件大致可以分为三个能力层级:基础解析型、智能匹配型、自主学习型。不同层级解决的问题完全不同,价格和效果也有数量级的差距。
基础解析型(准确率60-75%)
这类工具的核心能力是把非结构化简历(PDF、Word、图片)转化为结构化数据。代表产品包括部分招聘网站自带的解析功能、开源NLP解析引擎等。它们能识别姓名、学历、工作经历等基础字段,但对复杂排版、非标准表述的处理能力有限。一份设计师的创意简历,或者一份用表格排版的简历,经常让这类工具翻车。
智能匹配型(准确率75-88%)
在解析基础上增加了岗位匹配能力。工具会根据JD中的要求,对简历进行评分或排序。猎聘ATS、智联招聘企业版、e成科技等都属于这个层级。它们能做到按条件筛,比如筛选出5年以上Java经验+本科以上+在一线城市的候选人。局限在于:匹配逻辑相对固定,无法捕捉用人经理那些说不清但很重要的偏好。
自主学习型(准确率88-95%)
这是2026年的前沿水平。这类系统不只是按规则筛选,而是通过HR的每一次操作——哪些简历被推进到面试、哪些被淘汰、面试官的反馈是什么——持续学习企业的用人偏好。Moka AI的招聘管理系统中的招聘Eva就是这个层级的代表,它具备长期记忆能力,能记住每次筛选和面试的反馈,让筛选模型越用越精准。
你可能不知道的:AI筛选的核心瓶颈不是算法,是数据
很多企业在选型时只关注AI算法多先进,但据LinkedIn 2026年人才趋势报告数据,影响AI简历筛选效果的因素中,数据质量占52%,算法模型占28%,人工反馈机制占20%。
这意味着什么?一个拥有高质量历史招聘数据的企业,即使用中等水平的AI工具,效果也可能优于一个数据混乱的企业用顶级AI。
具体来说,数据质量包含三个维度:
简历数据的完整度。 企业人才库里积累了多少简历?这些简历的字段完整率如何?如果80%的简历只有姓名和电话,AI再聪明也无从判断。
招聘行为数据的丰富度。 过去两年,HR对每份简历的操作记录是否完整?推进、淘汰、标记的原因是否有记录?这些行为数据是AI学习什么是好简历的教材。
反馈闭环的完整性。 候选人入职后的表现数据是否回流到筛选模型?一个能跑通筛选→面试→入职→绩效全链条数据的系统,6个月后的筛选准确率比初始状态高出40%以上。
这就是为什么单独购买一个AI筛选插件,效果往往不如使用一体化招聘系统内置的AI能力。数据孤岛是AI筛选最大的敌人。
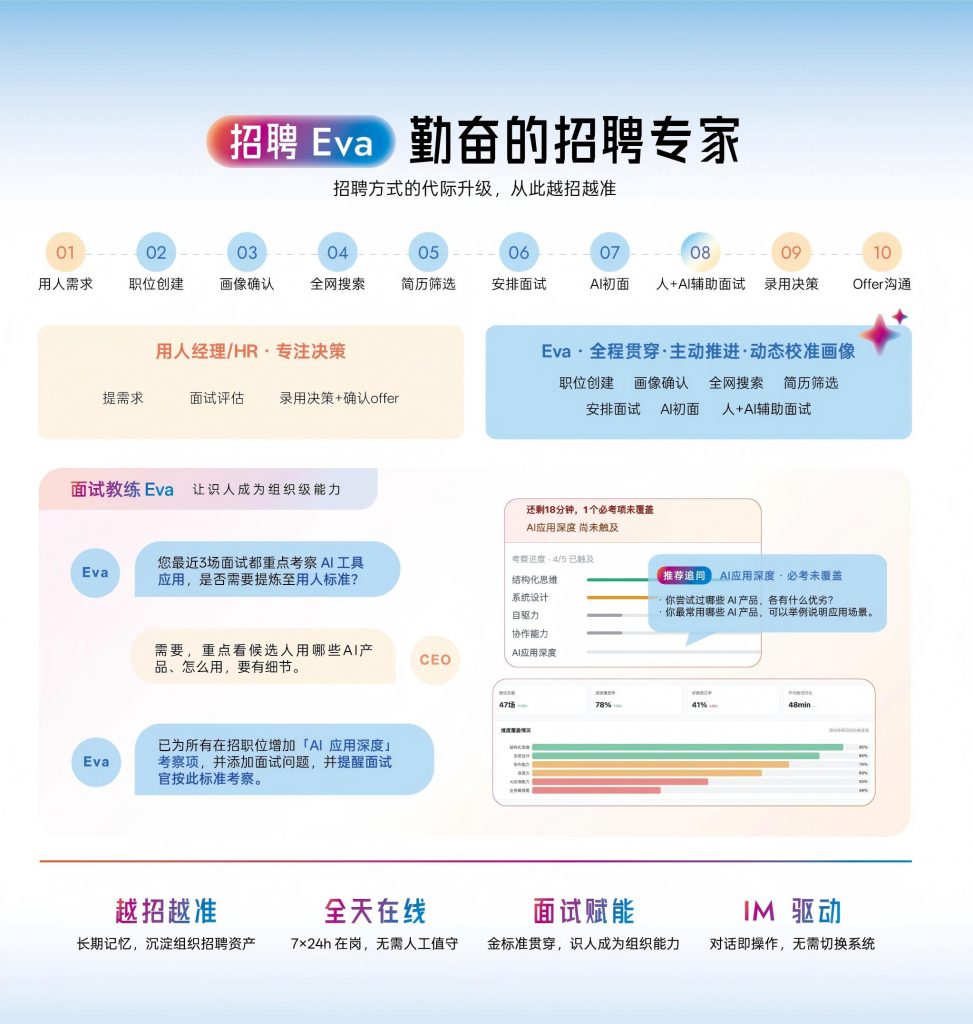
自主学习能力的差距最影响长期ROI。 短期看,各家工具的筛选效果差距在10-15%之间;但使用6个月后,具备自主学习能力的系统会因为数据飞轮效应把差距拉大到25-35%。Moka AI的招聘Eva之所以在这个维度领先,是因为它不只记录HR的操作,还能记住面试官的反馈偏好,形成组织级别的识人记忆。
与HCM系统的打通程度决定了数据闭环质量。 如果AI筛选只是一个独立模块,它永远无法获得候选人入职后的绩效数据,也就无法验证和优化自己的筛选标准。
不同企业规模的选型策略:别为用不上的功能买单
据HR科技行业调研,企业在AI简历筛选工具上的投入,50人以下企业年均花费1.2万元,200-500人企业年均4.8万元,500人以上企业年均12-30万元。但投入与满意度之间并非线性关系——200-500人规模的企业满意度反而最高,达到67%。
这个数据的启示是:关键不在于花多少钱,而在于工具能力是否匹配企业当前的招聘复杂度。
快速扩张期的互联网公司(半年内招100人以上): 最需要的是筛选速度和渠道聚合能力。每天涌入50-100份简历,HR团队来不及逐一看。这类企业需要的AI筛选工具必须具备:高并发处理能力、多渠道简历自动归集、快速初筛+人工复核的协作流程。招聘Eva在这个场景下的价值在于,它不只做初筛,还会主动推进流程——自动给通过初筛的候选人发送面试邀约,把HR从机械操作中解放出来。
稳定期的制造业企业(月均招聘20-30人): 招聘量不大但岗位多样性高,从产线工人到研发工程师都要覆盖。这类企业的痛点不是量,而是不同岗位的筛选标准差异大。需要AI工具能针对不同岗位类型建立独立的筛选模型,而不是一刀切。
专业服务公司(律所、咨询、会计师事务所): 候选人同质化高,简历表面信息差异小,筛选的核心是识别隐性素质——项目复杂度、客户规模、实际贡献度等。这类场景对AI的语义理解能力要求最高,基础解析型工具基本无法满足需求。
AI筛选的下一步:从帮你筛到替你找
据招聘数据分析平台的统计,2026年使用AI简历筛选的企业中,已有31%开始使用AI主动寻源功能——系统不再等HR上传简历,而是根据岗位需求主动从人才库中搜索匹配的候选人并推送给HR。
这是一个根本性的转变。传统AI筛选的逻辑是来一份简历,判断一份;而新一代AI同事的逻辑是理解你要什么人,主动去找、去推荐、去激活。
Moka AI的招聘Eva在这个方向上走得较远。它能做到:当一个新岗位发布时,自动扫描企业历史人才库中的沉睡简历,找出过去曾投递过类似岗位但未被录用的候选人,评估他们当前是否匹配(结合时间维度,比如工作年限增长、技能更新),然后生成推荐列表供HR参考。据使用企业反馈,这个功能平均能将岗位首次推荐到面试的时间从5天缩短到1.5天。
这背后的趋势判断是:到2027年,AI筛选这个概念本身会被淘汰,取而代之的是AI招聘同事——一个能理解需求、主动寻人、推进流程、持续优化的完整角色。 单一功能的筛选工具会逐渐被整合到更大的AI同事系统中。
选型时最该问供应商的三个问题
基于对47家企业选型过程的跟踪研究,最终选到满意工具的企业,在选型阶段问了这三个关键问题:
系统用了6个月后,筛选准确率会比现在高多少? 这个问题直接测试供应商是否具备自主学习能力。如果回答是保持一致的高水准,大概率是静态规则引擎;如果能给出基于数据飞轮,预计提升15-20%的具体数字,说明具备真正的学习机制。
你们的AI筛选和面试评估数据是否打通? 如果筛选和面试是两个独立模块,AI永远只能基于简历表面信息做判断。打通后,AI能学到简历上写了5年经验但面试表现只有3年水平这类深层规律。
候选人入职后的绩效数据能否回流到筛选模型? 这是最终极的验证:你筛出来的人,到底好不好用?能做到这一步的供应商,筛选模型的长期准确率会远超同行。
想看看 AI 同事系统能为你的招聘团队带来多大改变?
Moka AI 为中大型企业提供 AI 原生的智能招聘解决方案,招聘 Eva 覆盖从简历筛选到人才激活的全流程,越用越懂你的用人标准。立即免费试用,用数据验证效果。