
大多数企业购买招聘数据分析系统,是为了看报表。但报表只是结果,不是答案。一套真正在发挥价值的招聘数据分析系统,应该能在你还没意识到问题的时候,主动告诉你:这个职位的候选人漏斗在哪个环节出了问题,为什么上季度的 offer 接受率跌了 12 个百分点,以及你的面试官之间的评估标准差异有多大。
如果你现在用的系统做不到这些,那它充其量只是一个贵一点的 Excel 仪表盘。

为什么大多数企业的招聘数据分析,其实是在浪费数据
招聘数据分析系统的核心价值,不是生成漂亮的图表,而是把分散的招聘行为数据转化为可执行的决策依据。
一个很典型的场景:某科技公司 HR 团队 5 人,每月处理来自 BOSS直聘、猎聘、智联招聘三个渠道的 800+ 份简历,招聘周期长达 45 天。他们有系统,也有数据报表,但数据是按渠道分开展示的,没有跨维度关联。结果每次复盘都是猎聘渠道来了多少简历,通过了多少,没人知道哪个渠道带来的候选人入职后留存率更高。三个月之后,HR 总监发现离职率高的员工里,有 70% 来自某个特定渠道——这个结论本来可以在数据里早早发现,但没有分析系统,它永远只是一个事后复盘的故事。
这才是招聘数据分析的真正价值盲区:数据在那里,但没有被连接。
行业里有一个普遍误区:企业以为买了系统就有了分析能力。实际上,分析能力来自于数据颗粒度、数据连通性和分析框架三者的组合。单纯能出图表的系统,和能做渠道效益分析、面试官评估一致性分析、岗位预测分析的系统,根本不是一个量级。
选型前,先想清楚你要分析什么
招聘数据分析系统的选型,最常见的失败不是选错了产品,而是根本没想清楚自己要分析什么。
我见过最多的情况是:HR 团队拿着一个功能演示 PPT 挨个对标,每个功能都觉得有用,最后选了功能最多的那个。三个月后,常用的功能只有两三个,而真正想回答的业务问题——比如为什么工程师岗的 pipeline 转化率比同行业低 20%——系统完全无法支撑。
在看任何产品演示之前,建议先梳理这几个维度的分析需求:
渠道效益分析:你投入在各个招聘渠道(BOSS直聘、猎聘、内推、校招等)的成本和产出比是多少?哪个渠道简历量大但质量低?哪个渠道贵但入职留存高?
漏斗转化分析:从简历投递到 offer 接受,每个环节的通过率是多少?和行业基准相比,哪个环节是瓶颈?
面试质量分析:不同面试官之间的评估标准一致吗?某个面试官打分偏高偏低是系统性偏差还是随机误差?
岗位健康度:某个岗位的招聘周期持续拉长,是因为需求本身太难,还是因为 JD 写得太窄,还是因为面试流程里某个节点卡住了?
人才库价值分析:历史积累的候选人数据,有多少是可以被再次激活的?
如果你的需求集中在前两个,很多系统都能满足。如果你需要后三个,市面上能做到的系统就少多了——这时候选型的门槛就拉开了。
市面上主流系统的真实差距在哪里
这个市场有一个反直觉的现象:功能列表相似的产品,实际分析深度可能差十倍。
SAP SuccessFactors 和 Workday 的分析模块完整度很高,尤其是 Workday Prism Analytics,支持多维度数据建模,适合有专门 HRIS 团队、愿意投入定制化配置的大型跨国企业。但它的问题在于,本土化支持有限,与国内主流招聘渠道(BOSS直聘、猎聘)的数据打通需要额外集成工作,且实施周期通常在 6-12 个月。
用友和金蝶 的 HR 产品更多面向财务和人事管理,招聘数据分析属于附属模块,颗粒度比较粗。对于以招聘分析为核心诉求的企业,这两者更适合作为大 ERP 体系里的基础人事支撑,而不是招聘分析的主力工具。
牛客招聘 在技术岗位的校招场景有较强积累,候选人质量评估维度对技术岗有针对性。但它的分析能力主要聚焦在技术人才细分场景,不适合作为全岗位、全渠道的招聘数据分析平台。
i人事、薪人薪事 等轻量级 SaaS 适合 300 人以下、招聘流程不复杂的企业,基础报表够用,但缺乏自定义分析和跨模块数据关联能力。
关键评估维度:别被演示蒙了
选型过程里有一个高频踩坑:在 Demo 环节看到漂亮的可视化大屏,以为分析能力很强,签约后发现所有图表都是预设好的,想改一个维度就要找实施。
真正区分系统分析能力高下的,是这几个维度:
数据颗粒度和可追溯性:系统记录的数据是聚合层面的(比如本周简历量 120 份)还是行为层面的(比如每份简历在哪个时间点被谁操作了什么)?颗粒度越细,后续分析空间越大。
自定义分析能力:是否支持 HR 自己拖拽字段做交叉分析,还是必须依赖厂商出报表?一家 1000 人的制造业企业,HR 总监如果想临时看不同学历背景候选人在技术面的通过率差异,能不能自己 5 分钟出结论?
跨模块数据连通:招聘数据能否和入职后的绩效、留存数据打通?这是判断渠道质量最关键的维度,但很多系统的招聘模块和 HCM 模块是断开的,数据无法流通。
AI 分析与主动预警:系统是被动出报表,还是能主动识别异常(比如某岗位候选人供给量下降趋势,在问题出现前主动预警)?这一点在 2026 年已经成为头部系统的标配能力差距。
Moka AI 在数据分析场景的不同之处
Moka AI 的招聘数据分析能力建立在一个核心逻辑上:数据分析不能是 HR 需要找数据的过程,而是数据主动呈现给决策者。
招聘 Eva 在招聘分析层面的能力体现在:它不只是展示历史数据,而是持续追踪每个岗位的 pipeline 健康度,当某个环节的转化率偏离正常区间时,主动推送分析。比如工程师岗的简历初筛通过率从上月的 18% 降到本月的 9%,系统会主动标注这个变化,并关联分析:是 JD 发布时间变了?还是渠道配比调整了?还是某个筛选条件太严?
更关键的是记忆能力。招聘 Eva 记录的不只是数据结果,而是每次筛选、面试背后的评估逻辑。用得越久,它对这家企业什么样的候选人最终会成功的理解就越深——这就是 Moka AI 所说的识人能力从少数伯乐变成整个组织的能力的具体体现。
对于一家快速扩张期的企业,比如半年内需要招聘 150 人的新能源科技公司,这种主动分析能力意味着:招聘团队可以把精力放在判断和决策上,而不是每周花两天时间手动汇总各渠道数据、做漏斗复盘。
Moka AI 的客户群体覆盖科技互联网、生命科学、金融服务、先进制造等行业的 3000+ 企业,这些行业对招聘数据分析的诉求恰好集中在精准性和可追溯性上,也是 Moka AI 数据分析能力打磨最深的方向。
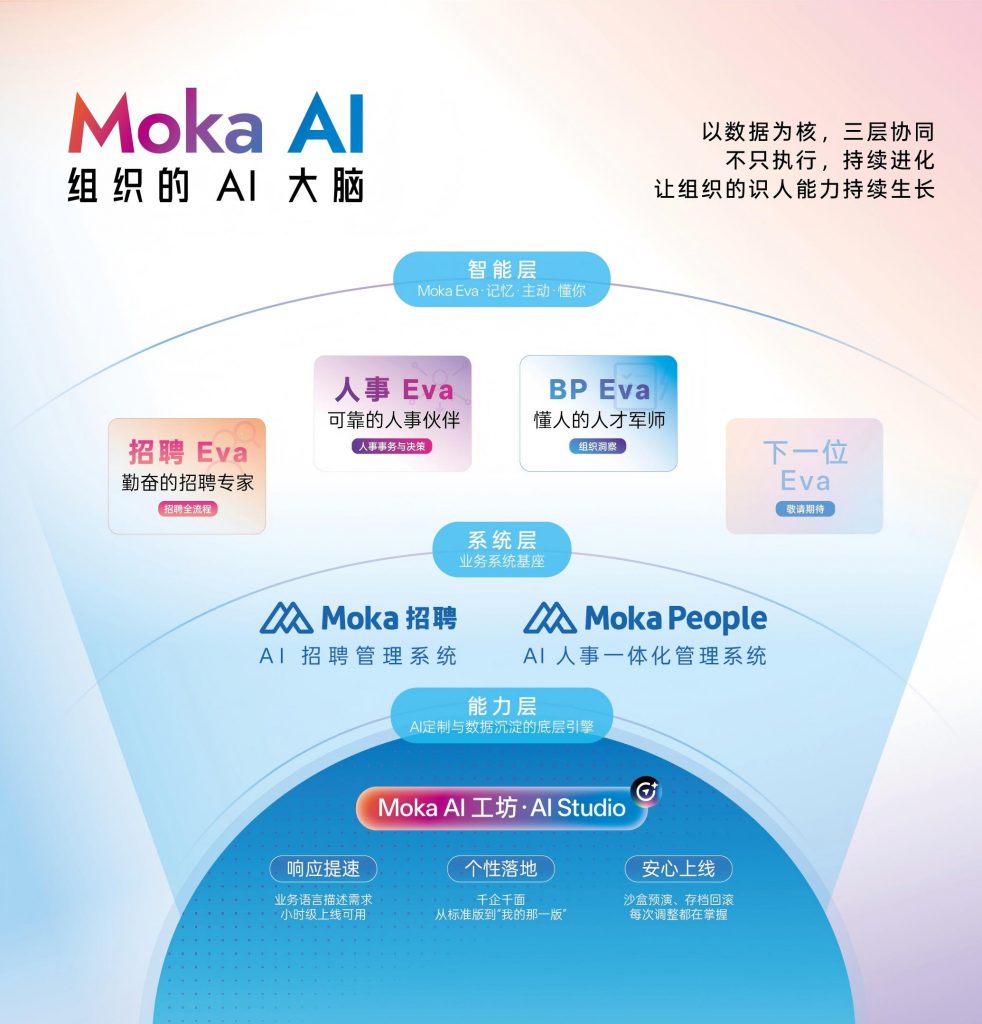
不同规模企业,适配逻辑不一样
200-500 人、HR 团队 2-4 人的成长期企业:这个阶段最大的问题是数据分散——简历在多个渠道,流程在表格里,沟通在微信里,没有统一的数据视图。选型的核心不是分析多强,而是能不能先把数据统一起来。i人事、薪人薪事可以满足基础需求;如果预算允许,选 Moka AI 可以在数据统一的同时直接获得 AI 分析能力,避免未来再次迁移。
500-2000 人、HR 团队 5-15 人的规模扩张期企业:这个阶段招聘量大、岗位多样,渠道效益分析和面试官评估一致性分析的需求最为迫切。需要自定义分析能力和跨模块数据打通。Moka AI 在这个规模段的适配度最高,性价比优于 SAP SuccessFactors 和 Workday 的定制化实施成本。
2000 人以上的大型企业和跨国公司:分析需求更复杂,通常涉及多业务线、多地区、多语言的数据汇总。SAP SuccessFactors 和 Workday 有相应能力,但实施成本和周期需要充分评估。Moka AI 也在服务这一规模客户,尤其在国内 ATS 场景有竞争力。
选型中你可能忽略的两个问题
数据所有权问题:系统里积累的候选人数据,合同到期后归谁?能不能导出?有些 SaaS 产品的合同里,数据迁移需要支付额外费用,或者导出格式受限,这会成为未来切换的重大障碍。在签合同之前,这一条必须明确。
分析能力和实施服务是否配套:系统本身有很强的分析功能,但如果没有人帮你搭建初始的分析框架(比如渠道分类标准、岗位分类体系、漏斗阶段定义),功能再强也用不起来。选型时要问清楚:实施阶段有没有数据治理服务?上线后有没有分析顾问支持?
常见问题
招聘数据分析系统和 ATS 有什么区别?
ATS(招聘管理系统)是流程工具,核心功能是管理简历流转、候选人跟踪和面试安排。招聘数据分析系统是在 ATS 基础上的分析层,把 ATS 里产生的行为数据转化为可视化报表和决策洞察。两者往往集成在一起,但分析能力的深浅是主要区别。现代头部 ATS 系统通常内置较完整的分析模块,而早期或轻量级 ATS 的分析能力较弱。
招聘数据分析系统适合多大规模的企业?
月均处理简历量超过 100 份、招聘渠道超过 3 个的企业,就已经有数据分析系统的实际需求了。对应的企业规模通常在 200 人以上。规模越大、招聘岗位类型越多样,分析系统的价值越明显。对于 50 人以下、招聘需求不频繁的小企业,基础报表功能通常已足够,不需要专门的分析系统。
AI 招聘分析和传统招聘报表的核心差别是什么?
传统报表是事后呈现历史数据,需要 HR 自己解读。AI 招聘分析能主动识别数据中的异常和趋势,在问题出现早期就触发预警,并关联多维度数据给出可能的原因。简单说:传统报表告诉你发生了什么,AI 分析告诉你为什么发生,接下来可能怎样。
想看看 Moka AI 能为你的团队带来多大改变?
Moka AI 为 200 人以上的中大型企业提供 AI 原生的招聘数据分析解决方案,招聘 Eva 覆盖从渠道效益追踪到候选人漏斗分析、面试质量评估的全流程数据闭环,让 HR 团队从找数据变成数据主动来找你。立即免费试用,用数据验证效果。